ViZDoom allows developing AI bots that play Doom using visual information (the screen buffer). It is primarily intended for research in machine visual learning, and deep reinforcement learning, in particular.
So far ViZDoom was cited in over 666 articles and used in many of them as a research environment!
In 2022 ViZDoom joined Farama Foundation.
Main features
- Multi-platform (Linux, macOS, Windows)
- API for Python, C++ and partially Lua, Java and Julia
- Gymansium wrapper / OpenAI Gym wrapper
- Easy-to-create custom scenarios (visual editors, scripting language and examples available)
- Async and sync single-player and multi-player modes


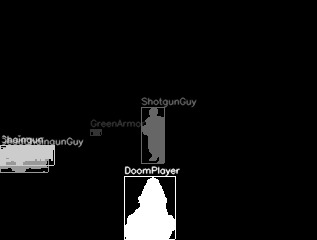

- Fast (up to 7000 fps in sync mode)
- Lightweight (few MBs)
- Customizable resolution and rendering parameters
- Access to the depth buffer (3D vision)
- Automatic labeling game objects visible in the frame
- Access to the audio buffer (seeings + hearing)
- Off-screen rendering
- Episodes recording and replaying
- Time scaling in async mode
- It is Doom!
Community
ViZDoom is based on ZDoom, the most popular modern source-port of Doom. This means compatibility with a huge range of tools and resources that can be used to create custom scenarios, availability of detailed documentation of the engine and tools and support of Doom community.
